
The Experience-Led AI Framework
Why Contact Center AI Fails and How Ecosystem Architecture Fixes It
Add bookmark

Abstract
The Problem: Enterprise contact centers are investing heavily in AI—deploying chatbots, sentiment analysis, speech analytics, and generative AI layers—yet resolution rates, repeat contacts, and customer satisfaction remain stubbornly flat. Gartner projects that over 40% of agentic AI projects will be cancelled by 2027. The prevailing explanation blames model performance. This article identifies a deeper cause: architectural fragmentation. Organisations are accumulating AI tools in functional silos where each optimises its own metric without contributing to the intelligence of adjacent systems.
The Framework: This article introduces the Experience-Led AI Framework, a four-layer architecture for building AI ecosystems that compound: (1) define resolution experiences, (2) build a shared data foundation, (3) deploy closed-loop AI engines, and (4) measure ecosystem intelligence. The framework includes four original diagnostic constructs—the Silo Paradox, the Ecosystem Leverage Ratio, the Context Retention Score, and Learning Velocity—designed to help leaders distinguish genuine ecosystem intelligence from rebranded tool portfolios.
The framework is grounded in the author's experience leading the product strategy for two enterprise-scale AI programmes at Dell Technologies:
[1] a digital supply chain transformation in which the author served as the product management and strategy lead for the initiative with MIT researchers and
[2]STRIDE (Smart Troubleshooting and Resolution with Intelligent Dispatch Engine), an AI-driven service ecosystem that the author directed from product vision through production deployment, recognised with the 2025 TSIA STAR Award for Innovation in AI for Service Excellence
The cross-domain consistency of the architectural principle across both programmes—spanning different technology generations, organisational contexts, and operational domains—is what elevates it from a project-level learning to a field-level methodology with practitioner application.
1. Introduction
Gartner projects that over 40% of agentic AI projects will be cancelled by the end of 2027, citing escalating costs, unclear business value, and inadequate risk controls [3]. For contact center leaders, this should be more than a statistic. The contact center has become the primary deployment environment for enterprise AI, and the failure pattern Gartner describes is already visible in organisations that have spent years and significant capital building AI capabilities that do not compound.
The prevailing explanation for these failures focuses on model performance: insufficient training data, immature natural language understanding, poor intent coverage. This article advances a different explanation. The failure is architectural. It results from deploying AI tools in functional silos where each system optimises its own metric without contributing to or benefiting from the intelligence of adjacent systems. The problem is not that the tools are weak. The problem is that the operating model treats them as independent investments rather than components of a collective intelligence system.
This article introduces the Experience-Led AI Framework: a four-layer architecture that gives contact center leaders a structured methodology for building AI ecosystems. The framework includes four original diagnostic constructs—the Silo Paradox, the Ecosystem Leverage Ratio, the Context Retention Score, and Learning Velocity—designed to help organisations identify whether their AI portfolio is generating collective intelligence or merely accumulating individual tools.
The synthesis presented here is what leading both programmes revealed: a consistent architectural principle that operates across domains, time periods, and technology generations. The details of each programme and its outcomes are documented in references [1] and [2]; this article focuses on the cross-domain principle they share and the framework it produces.
The remainder of this article is structured as follows. Section 2 introduces the Silo Paradox. Section 3 presents the four-layer framework and its closed-loop engine design. Section 4 introduces four original ecosystem metrics. Section 5 provides an implementation playbook. Section 6 offers a readiness diagnostic. Section 7 addresses future directions.
2. The Silo Paradox: Why More AI Produces Less Intelligence
A typical enterprise contact center in 2026 operates five to eight distinct AI systems: conversational AI, sentiment analysis, speech analytics, quality management, workforce optimisation, knowledge management, and increasingly one or more generative AI layers. Each was acquired to address a specific operational need. Each reports metrics that individually appear healthy.
Yet the cumulative performance of these systems rarely matches the sum of their individual contributions. Resolution rates remain stubbornly below expectations. Repeat contact rates persist at levels that predate AI investment. Agents continue to re-gather context that exists somewhere in the stack but is inaccessible at the point of need.
This gap between individual tool performance and collective operational outcome is what this article terms the Silo Paradox:
The Silo Paradox: the more AI tools an organisation deploys in isolation, the less intelligent its operation becomes as a whole. Each tool optimises its own metric; none optimise for resolution.
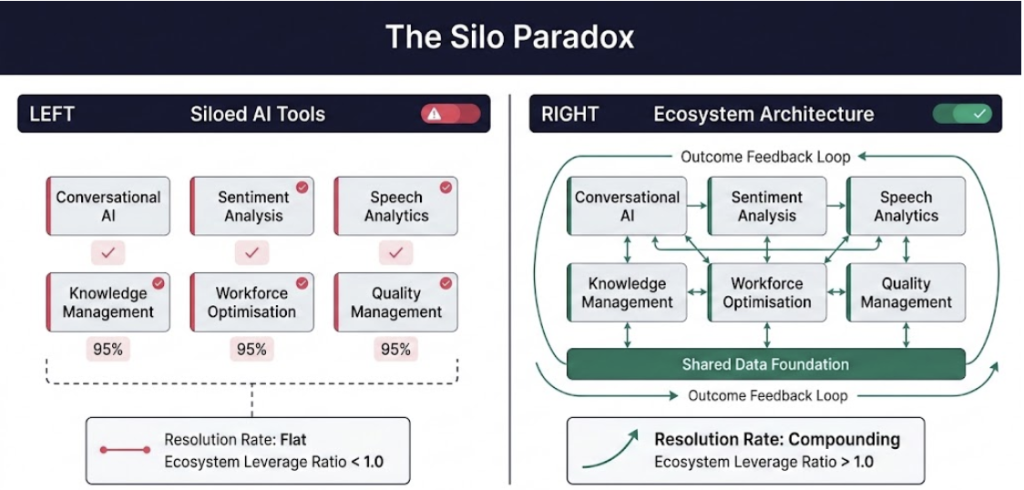
Figure 1: The Silo Paradox. Left: siloed AI tools, each optimising independently with no shared context. Right: ecosystem architecture where engines share a common data foundation and produce compound intelligence. The Ecosystem Leverage Ratio measures whether an organisation is operating on the left or the right.
The Silo Paradox is not a technology problem. It is an organising principle problem. AI tools are typically procured by different functional owners with independent budget cycles and success metrics. Most commercial AI platforms are designed to serve human interfaces, not to expose their inference outputs as inputs for adjacent systems. Organisational measurement frameworks track tool-level KPIs rather than system-level outcomes. The result is an organisation that can point to AI everywhere and intelligence nowhere.
The construct emerged from a specific observation across both programmes referenced in this article. In the supply chain context, over 120 technology-organised use cases were individually sound but collectively incoherent until they were reorganised around stakeholder experiences [1]. In the service AI context, the same principle surfaced: three independently capable AI engines produced compound value only after they were architecturally connected through shared context and directed data flows [2]. The consistency of this pattern across two very different domains is what elevates it from a project-level learning to a field-level construct.
The structural reasons the Silo Paradox persists are worth naming explicitly. First, procurement fragmentation: AI tools are purchased by function, not by outcome. Second, interface isolation: most AI platforms are designed to interact with humans, not with other AI systems. Third, metric misalignment: tool-level KPIs (containment rate, intent accuracy, detection precision) can all improve simultaneously while system-level outcomes stagnate. Fourth, data fragmentation: without a shared data foundation, every tool operates on its own version of the truth, making genuine integration architecturally impossible.
3. The Experience-Led AI Framework
The Experience-Led AI Framework emerges from a specific inversion of the dominant organising question for AI strategy. The technology-first question asks: what AI capabilities can we deploy? It produces a portfolio of independent tools. The experience-led question asks: what resolution experiences must we deliver, and what capabilities does each require? It produces an integrated architecture.
The framework comprises four sequential layers, each dependent on the layer below it.
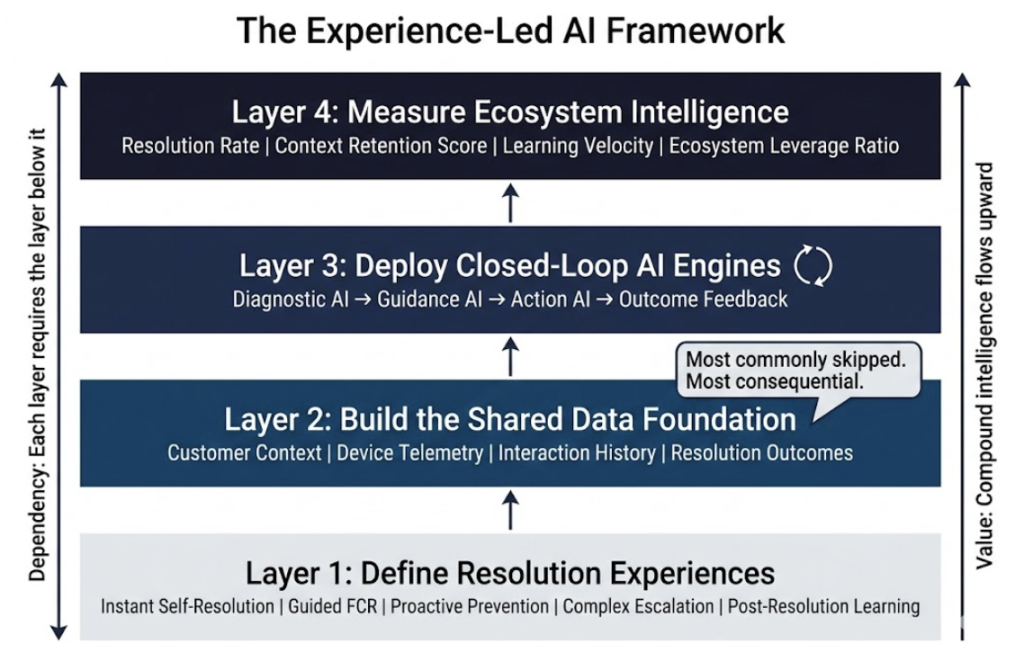 Figure 2: The Experience-Led AI Framework. Four-layer architecture where each layer depends on the layer below it. Layer 2 (Shared Data Foundation) is the most commonly skipped and the most consequential prerequisite.
Figure 2: The Experience-Led AI Framework. Four-layer architecture where each layer depends on the layer below it. Layer 2 (Shared Data Foundation) is the most commonly skipped and the most consequential prerequisite.
3.1 Layer 1: Define Resolution Experiences
The first layer replaces technology-organised AI initiatives with outcome-defined workstreams. Rather than a roadmap organised by capability (chatbot, analytics, dispatch automation), the organisation defines a small number of resolution experiences that represent the complete range of customer journeys its AI estate must serve. Five experience categories cover the majority of contact center AI scope:
Instant self-resolution: the customer resolves without agent involvement.
Guided first-contact resolution: the agent resolves in a single interaction with AI support.
Proactive prevention: the issue is detected and addressed before customer contact.
Complex escalation with context: multi-touch issues are routed with full diagnostic history preserved.
Post-resolution learning: every interaction improves future resolution performance.
Each AI investment should map explicitly to one or more of these experiences. Tools that cannot be mapped to a resolution experience are candidates for reassessment rather than further investment. In practice, applying this mapping exercise has clarified priorities within large AI portfolios within weeks, enabling teams to concentrate investment on initiatives that connect directly to a customer outcome and defer those where the connection is indirect [1].
3.2 Layer 2: Build the Shared Data Foundation
The shared data foundation is the most consistently underestimated layer and the most consequential for ecosystem performance. It is the infrastructure that enables all AI engines to operate from a common, consistent view of the customer, the interaction, and the operational context.
Without this layer, every AI capability operates on its own version of the truth. The learning from leading product strategy for both the digital supply chain transformation [1] and the STRIDE service AI ecosystem [2] is unambiguous: organisations that skip the shared data foundation in favour of faster capability deployment find that their AI investments produce diminishing returns as the portfolio grows, because each new capability creates a new data silo rather than enriching a shared context.
For contact centers, the shared data foundation must capture and maintain four categories of context in near-real-time: customer identity and interaction history across all channels; device and product telemetry where applicable; interaction transcripts, intent signals, and sentiment state; and resolution outcomes linked back to the specific AI-assisted decisions that contributed to them.
The canonical data model approach—where inputs from disparate source systems are normalised before being routed to downstream applications—provides the architectural pattern that makes this practical at enterprise scale [1]. The investment required is significant. The cost of not making it is higher.
3.3 Layer 3: Deploy Closed-Loop AI Engines
With resolution experiences defined and a shared data foundation in place, AI capabilities can be deployed as an interconnected ecosystem rather than as independent tools. The distinguishing architectural characteristic of Layer 3 is directionality: every AI engine is designed to both consume context from adjacent engines and produce outputs that feed adjacent engines.
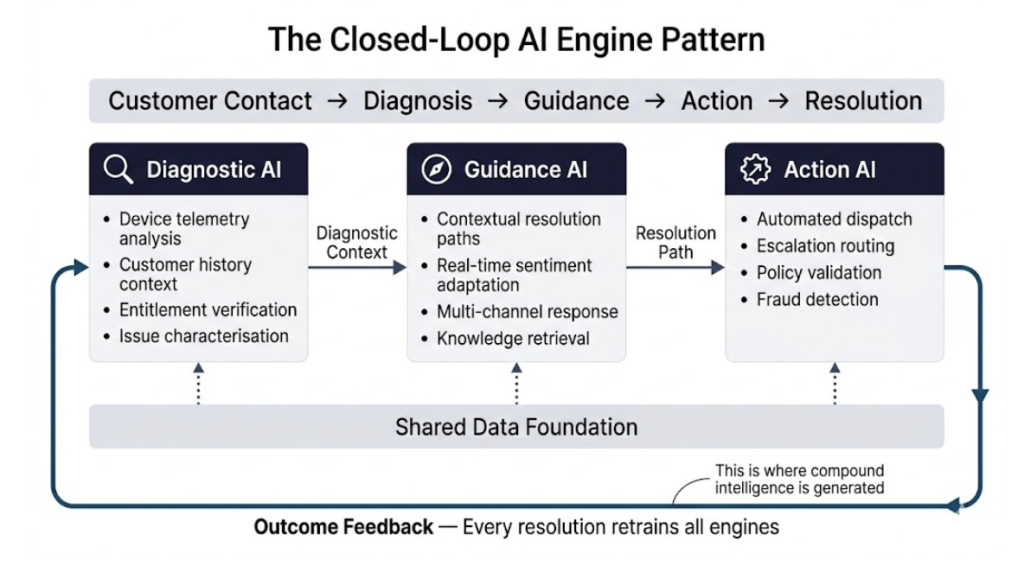
Figure 3: The Closed-Loop AI Engine Pattern. Diagnostic AI, Guidance AI, and Action AI operate as an interconnected ecosystem. Outcome feedback from every resolved case flows back to retrain all engines simultaneously, producing compound intelligence over time.
The generalised closed-loop pattern comprises three functional roles that apply across contact center AI architectures. Diagnostic AI consumes device telemetry, customer history, and entitlement data from the shared foundation to characterise the likely issue before any human interaction begins. Guidance AI receives diagnostic context supplemented by real-time sentiment and session history to generate contextually relevant resolution paths. Action AI receives validated diagnostic and guidance outputs to execute service decisions—whether dispatch, escalation, or automated resolution—with documented accuracy at enterprise scale.
The critical mechanism that closes the loop is outcome feedback. Every resolved case and every failed resolution generates a signal that flows back to retrain all engines simultaneously. When a particular combination of signals predicts a resolution path that downstream AI later confirms, the diagnostic engine strengthens that association. The ecosystem as a whole accumulates intelligence that no individual engine could develop in isolation. The Closed-Loop Corrective Action system documented in [2] operationalises this principle in production at enterprise scale.
The core architectural insight is that connection design must precede capability design. Specifying how engines will share context, what structured outputs each will produce, and how outcomes will feed back to retrain the ecosystem—these decisions must be made before individual capability development begins. Organisations that develop capabilities first and integrate later consistently recreate the Silo Paradox at the engine level.
3.4 Layer 4: Measure Ecosystem Intelligence
Standard contact center AI metrics are designed to evaluate individual tools, not collective performance. Containment rate, intent accuracy, detection precision: these metrics can all improve while ecosystem-level outcomes stagnate, because they measure what individual tools do rather than what the ecosystem achieves. This layer introduces four ecosystem-level metrics, detailed in Section 4.
4. Four Metrics for Ecosystem Intelligence
Resolution Rate measures the percentage of contacts where the customer’s underlying problem was solved, regardless of channel or interaction count. This replaces containment rate as the primary self-service metric. Containment measures whether the AI handled the contact. Resolution Rate measures whether the customer’s problem is actually gone.
Context Retention Score measures the percentage of diagnostic context successfully preserved across handoffs between AI systems and from AI systems to human agents. This quantifies the integrity of the shared data foundation in practice. A high score means customers never repeat information. A low score means the data foundation exists in theory but fails at handoff boundaries.
Learning Velocity measures the rate at which resolution outcomes improve model accuracy across the ecosystem over time. This determines whether the feedback loop is functioning. If Learning Velocity is flat, the organisation has deployed AI but has not built intelligence. The Closed-Loop Corrective Action system in [2] demonstrates Learning Velocity in production through continuous model retraining from closed cases.
Ecosystem Leverage Ratio measures, for every unit of investment in one AI capability, the improvement in adjacent capabilities without separate investment. This is the signature metric of closed-loop architecture. A ratio above 1.0 confirms the ecosystem is generating compound returns. A ratio at or below 1.0 indicates the deployment is operating as silos regardless of how the architecture is described.
The Ecosystem Leverage Ratio warrants particular attention because it is what distinguishes genuine ecosystem architecture from rebranded tool portfolios. In both programmes that ground this framework, improvements in downstream AI capabilities were directly attributable to improved inputs from upstream systems—without any separate investment in those downstream models [1][2]. That compounding pattern, observed independently across two distinct domains, is what gives the ratio its theoretical grounding and practical diagnostic value.
5. Implementation Playbook for Contact Center Leaders
The following five-step sequence translates the framework into an actionable implementation pathway. The sequence is ordered deliberately: each step creates the preconditions for the next.
Step 1: Map Your Resolution Experiences. Begin with a structured audit of customer journeys, not AI capabilities. For each major contact type, define the experience the customer should have rather than the technology that will deliver it. Document five to eight resolution experiences that cover at least 80% of contact volume. The discipline of defining experiences before technologies is essential. This mapping exercise typically involves cross-functional stakeholder engagement—interviews across functions, focus groups with operational teams—and delivers clarity within weeks rather than months [1].
Step 2: Audit Your Stack for Closed-Loop Readiness. For each AI system currently in operation, answer three questions. Does it receive structured context from any other AI system as an input? Does it produce structured outputs consumed by any other AI system? Do its outcomes feed back into any retraining process? Systems that answer no to two or more questions are silos.
Step 3: Build or Validate the Shared Data Foundation. Before deploying any new AI capability, verify that the shared data foundation can provide that capability with the context it requires from adjacent systems. Organisations that skip this step consistently pay for it in later integration costs and capability ceilings.
Step 4: Deploy in Closed Loops, Not Parallel Lines. When adding new AI capabilities, begin with the connection design before the capability design. Specify explicitly: what context does this capability consume, what outputs does it produce, and how do its outcomes feed back into the ecosystem? Capabilities that cannot answer these questions clearly should be redesigned or deferred.
Step 5: Instrument Ecosystem-Level Metrics. Implement Resolution Rate, Context Retention Score, Learning Velocity, and Ecosystem Leverage Ratio alongside existing tool-level metrics. Report them at the same level of organisational attention. The Ecosystem Leverage Ratio should be reviewed quarterly. A ratio consistently above 1.0 confirms the ecosystem is functioning as designed. A ratio drifting toward 1.0 is an early warning that architectural silos are re-emerging.
6. Contact Center AI Readiness Diagnostic
The following diagnostic provides a rapid assessment of an organisation’s current architectural position relative to the Experience-Led AI Framework.
| Diagnostic Question | If YES | If NO |
| Can you name 3–5 resolution experiences (not technologies) that define your AI roadmap? | Experience-led foundation in place | Likely deploying technology-first |
| Do your AI systems share a common data foundation? | Can build closed loops |
Building more silos |
| Does any AI system consume another AI system’s output as input? | Seed of an ecosystem exists | Collection of point solutions |
| Do you measure resolution outcomes, not individual tool metrics? | Can evaluate ecosystem value | Measuring activity, not intelligence |
| When one AI system improves, do adjacent systems benefit automatically? | Compound intelligence confirmed | Linear tools, not compound |
Scoring: 4–5 Yes: architecturally ready to scale the ecosystem. 2–3 Yes: foundational restructuring required before further AI investment. 0–1 Yes: discontinue new AI tool procurement and invest in the shared data foundation as an immediate priority.
7. Future Directions
Gartner projects that agentic AI will autonomously resolve 80% of common customer service issues by 2029 [4]. This projection is plausible, but only for organisations whose AI architecture can support genuine agency. An AI agent operating in a silo can automate a task. An AI agent operating within a closed-loop ecosystem—with access to diagnostic context, guided by resolution intelligence, and validated by outcome feedback—can resolve a problem.
Three emerging capability areas will define the next generation, and all require ecosystem architecture as a prerequisite. Autonomous service orchestration—where AI not only predicts a service failure but coordinates the response across supply chain, fulfilment, and service systems before the customer is aware—requires precisely the cross-domain data integration the shared foundation layer provides. Hyper-personalised service economics—where the system learns individual customer preferences for proactive intervention versus minimal contact—requires the learning velocity that closed-loop feedback produces. Predictive service as a commercial product—where customers pay a premium for guaranteed proactive support—requires the resolution rate and trust indicators that only ecosystem-level measurement can substantiate.
None of these capabilities are achievable inside a siloed AI architecture. All of them become natural extensions of a well-designed ecosystem. The investment case for experience-led architecture is therefore not only about correcting current underperformance—it is about creating the architectural preconditions for the capabilities that will define customer operations over the next five years.
8. Conclusion
The organisations that will define customer experience over the next five years are not those deploying the most AI tools. They are those building ecosystems where every capability compounds the value of every other.
The constructs introduced in this article—the Silo Paradox, the Ecosystem Leverage Ratio, the Context Retention Score, and the Learning Velocity metric—are grounded in documented, independently validated enterprise implementations [1][2] rather than in theoretical modelling alone. The author was selected to present this framework to senior executives at Customer Contact Week Orlando 2026 on the Main Stage and at CCW Executive Exchange Austin 2026, where the practitioner response has consistently identified the Silo Paradox and the Ecosystem Leverage Ratio as constructs that name problems organisations already recognise but have lacked precise language to diagnose.
Technology changes. The organising principle does not. Define the experiences. Build the foundation. Close the loop. Measure the ecosystem. That sequence, applied with discipline, is what separates AI transformation from AI experimentation.
References
[1] Borrella, I., Saenz, M.J., and Revilla, E. (2021). “Dell: Roadmap of a Digital Supply Chain Transformation.” Ivey Publishing Case W24797.
[2] Technology and Services Industry Association (2025). “Revolutionizing Customer Support with AI: The Dell STRIDE Advantage.” TSIA STAR Awards 2025 Featured Application. Award Category: Innovation in Leveraging Analytics and AI for Service Excellence.
[3] Gartner (2024). “Predicts 2025: Agentic AI Will Drive New Value and New Risks.” Gartner Research Note. https://www.gartner.com/en/newsroom/press-releases/2025-06-25-gartner-predicts-over-40-percent-of-agentic-ai-projects-will-be-canceled-by-end-of-2027
[4] Gartner (2025): “Predicts Agentic AI Will Autonomously Resolve 80% of Common Customer Service Issues Without Human Intervention by 2029” https://www.gartner.com/en/newsroom/press-releases/2025-03-05-gartner-predicts-agentic-ai-will-autonomously-resolve-80-percent-of-common-customer-service-issues-without-human-intervention-by-20290#:~:text=Gartner%20Predicts%20Agentic%20AI%20Will,call%201%20800%20213%204848



















